Imperative MPC: An End-to-End Self-Supervised Learning with Differentiable MPC for UAV Attitude Control
Modeling and control of nonlinear dynamics are critical in robotics, especially in scenarios with unpredictable external influences and complex dynamics. Traditional cascaded modular control pipelines often yield suboptimal performance due to conservative assumptions and tedious parameter tuning. Pure data-driven approaches promise robust performance but suffer from low sample efficiency, sim-to-real gaps, and reliance on extensive datasets. Hybrid methods combining learning-based and traditional model-based control in an end-to-end manner offer a promising alternative. This work presents a self-supervised learning framework combining learning-based inertial odometry (IO) module and differentiable model predictive control (d-MPC) for Unmanned Aerial Vehicle (UAV) attitude control. The IO denoises raw IMU measurements and predicts UAV attitudes, which are then optimized by MPC for control actions in a bi-level optimization (BLO) setup, where the inner MPC optimizes control actions and the upper level minimizes discrepancy between real-world and predicted performance. The framework is thus end-to-end and can be trained in a self-supervised manner. This approach combines the strength of learning-based perception with the interpretable model-based control. Results show the effectiveness even under strong wind. It can simultaneously enhance both the MPC parameter learning and IMU prediction performance.
Approach Overview
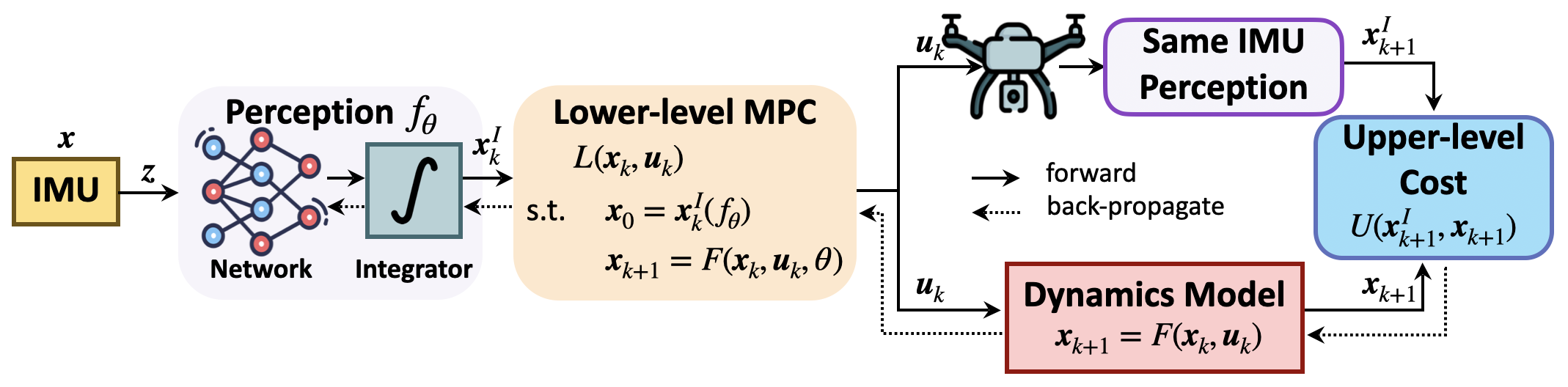
Our method integrates a perception network with a physics-based MPC optimizer to enable self-supervised learning for UAV control. The perception network processes raw IMU measurements to predict high-level MPC parameters (e.g., dynamics, objectives, constraints; UAV’s current state here), while the MPC solves for optimal state and control sequences under system dynamics constraints. We define the upper-level loss function as the discrepancy between dynamics calculated states and IMU-driven perception predicted states. Leveraging implicit differentiation via PyPose’s differentiable MPC (d-MPC), our method efficiently avoids costly unrolled gradient computations. This design enables end-to-end joint training, ensuring dynamically feasible and physically grounded learning without relying on labeled data.
Experiment Results
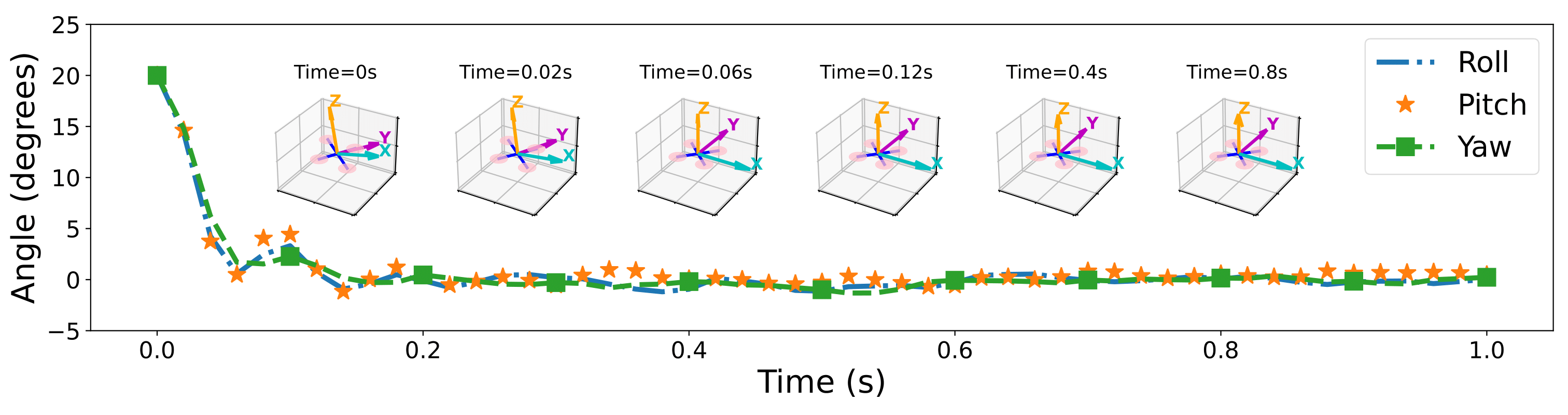
The UAV attitude quickly returns to a stable hover state for an initial condition of 20° using our iMPC as the controller.
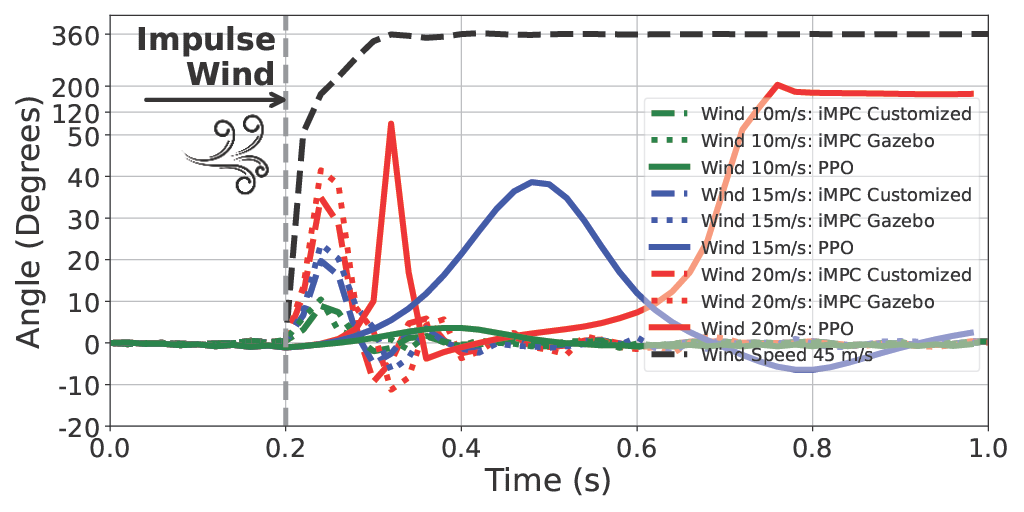
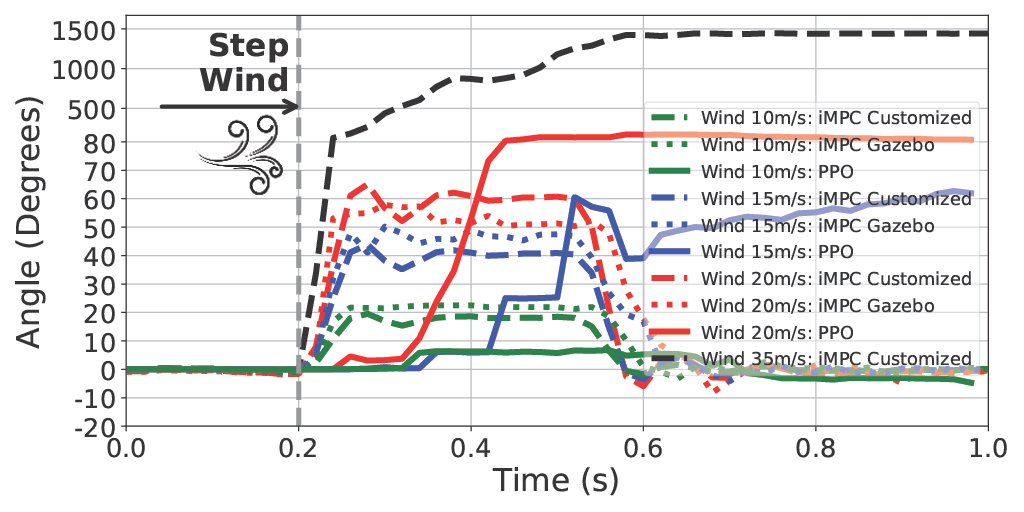
Control performance of iMPC and Reinforcement Learning Proximal Policy Optimization (PPO) under different levels of wind disturbance.
Learned Dynamics Parameters
We also evaluate the learning performance in the d-MPC. In particular, we treat the UAV mass and moment of inertia (MOI) as the learnable parameters.
| Initial Offset | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Initial | Error | Initial | Error | Initial | Error | Initial | Error | ||
| MOI | 50% | 0° | 0.96% | 10° | 2.67% | 15° | 3.41% | 20° | 2.22% |
| Mass | 50% | 0° | 1.69% | 10° | 0.85% | 15° | 1.43% | 20° | 0.32% |
BibTeX
@inproceedings{He2025iMPC,
author = {Haonan He and Yuheng Qiu and Junyi Geng},
title = {Imperative MPC: An End-to-End Self-Supervised Learning with Differentiable MPC for UAV Attitude Control},
booktitle = {Proceedings of the 7th Annual Learning for Dynamics & Control Conference},
year = {2025},
pages = {Accepted}
}